はじめに
LAPRASでは、Chat GPT などの大規模言語モデル(LLM)登場の以前から、AIを活用したプロダクト・機能を開発してきた。
AIを活用したプロダクト開発では、AIチームとプロダクト開発チームが緊密に連携し、協力して行うことが重要である。コンウェイの法則を持ち出すまでもなく、組織の構造とシステムのアーキテクチャは密接に関連しており、組織のコミュニケーションラインの設計とアーキテクチャの設計は切っても切り離せない関係にある。
本記事では、この観点から過去と現在のLAPRASが採用しているアーキテクチャとその背後にある考え方を詳しく紹介することで、LLM時代に考えるべきAIチームとプロダクト開発の協働のあり方についての考え方を紹介する。
過去の実装とその課題
LAPRASは、LLM登場以前からAIを活用した機能を提供してきたが、その過程でいくつかのアーキテクチャを試行し、課題を経験してきた。
まずは、過去に試ししてきたアーキテクチャと、その課題展を紹介する。
過去のアーキテクチャその1: マイクロサービス
最初のアーキテクチャでは、WebアプリサーバーとAIサーバーを、それぞれプロダクトチームとAIチームが独立したリポジトリおよびコンテナとして開発した。Webアプリサーバーは、AIサーバーが提供するAPIを呼び出すことで、AIによる分析結果を得る構成だった。
通常「マイクロサービス」というと、このような独立したサーバ群をHTTP API を通じて連携させるものを指すことが多いのではないかと思う。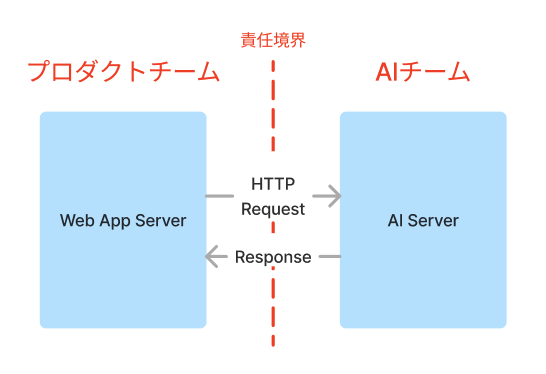
この構成はよく用いられる一方、AIを用いた開発で用いるには課題があった。
まず、AIチームがAI開発以外に関心を払わなければならないことが挙げられる。
AI開発は通常のプロダクト開発と異なり、AIアルゴリズム自体が不確定性を持っているため、開発の段階においてはなるべくAIアルゴリズムの開発に集中してほしい場合が多い。しかし、AIサーバーのAPIを責任境界とすると、AIチームは、AIサーバーのAPI設計や、HTTP経由での効率的なデータのやり取りや適切な例外処理の伝播、ロギング、並列処理の取り回し、コンテナの作成など、AIアルゴリズム以外に考慮しなければならないことが多くなってしまう。
また、運用の段階となると、AIチームが作成したAIサーバーはプロダクトチームからはブラックボックスになりやすく、性能的な問題が生じた際にプロダクトチームで対処することができない問題もある。
また、もう1つの問題は、APIによる責任境界の分離において、チーム間の独立性を保ちながら仕様変更を可能にすることが難しいことにある。
AIを用いた機能の開発や改修においては、入出力データの種類を増やしたり変更したりする必要がどうしても出てくる。APIを責任境界として仕様を一度しっかりと決めてしまうと、こうした仕様変更の際にドキュメンテーションや整合性の維持のための余分なコストがかかることになってしまう。
また、コードのAIサーバーのリリースを行う際には、WebAppサーバーとの整合性を維持するためにプロダクトチームとタイミングを合わせてリリースを行う必要がある。特に、AIチームはAI開発において試行錯誤を繰り返す必要があり、実験的な変更も含めて独自の開発サイクルでリリースを行いたいが、これがプロダクトチームに依存してしまうことで、依存関係や待ちが生じてしまう。仕様変更やモデルの変更の際にAPIのバージョンを切ることもできるが、些細な変更のたびにそれを行うのはオーバーヘッドが大きい。
これらの問題は、AIチームがプロダクトチームよりも専門的で小さなチームを志向しているLAPRASにおけるチーム構成によるものであるということもできる。
AIチームが単独でAIサーバー全体の開発・運用までを担当できるよう、AIエンジニア以外のエンジニアメンバーを含む混成チームとした場合は、このようなマイクロサービスの構成に合理性があるかもしれない。たとえば、AIの性能向上がビジネス上の成果に直接結びついているような場合には、安定的に ML Ops を回すことがより重要であるため、これを担当するチームとして独立したAIチームを混成メンバーで構成した方が良いであろう。
しかしながら、LLMの登場により、AIを用いた機能開発はますます「どう作るか」よりも「誰に何を届けるか」が重要となってきており、この状況においては、AIチームはPoCやプロトタイピングなど探索的な活動が多くなるため、マイクロサービス型のアーキテクチャは適さないと考えられる。
過去のアーキテクチャその2: ライブラリ
次のアーキテクチャは、AIチームが開発したコードをライブラリ(Pythonパッケージ)として提供し、プロダクトチームがそれをWeb App サーバーに組み込んで利用する構成である。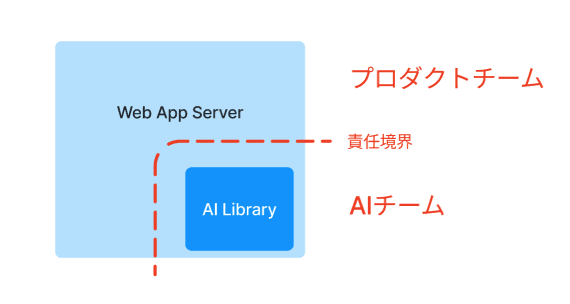
この構成では、マイクロサービス化による問題の多くが解決できる。
AIチームは、プロダクトチームに提供するライブラリの仕様を、関数やValue Objectの定義として簡易的に提供することができるし、サーバーのインフラ構築について考える必要もない。
また、AIチームは任意のタイミングでライブラリを更新することができ、プロダクトチームは更新されたライブラリの変更を取り込むと同時に、整合性を保つための変更を加えてからリリースすることができる。
この構成の唯一にして最大の問題点は、Web App サーバーとAIライブラリが同一の実行環境でなければならない点である。
まず第一に、Web App サーバーとAIライブラリは同一の言語(Python)の上で動かなければならないし、依存ライブラリも共有している必要がある。LAPRAS の場合、プロダクトの大部分はPython で書かれているため言語の問題は無いが、依存ライブラリのバージョンの問題は大きい。
特に、AI関連のオープンソースコミュニティは常に最新技術を取り入れるために変化が激しく、提供されるライブラリはしばしば後方互換性の無い変更も行われる。こういった最新のライブラリは、依存ライブラリも最新のバージョンを要求し、以前からWeb App サーバーに入っていたライブラリとバージョン不整合を起こしやすい。
依存ライブラリ関連のもう1つの問題として、AI系のライブラリは単純にライブラリのサイズが大きく、インストールにも時間がかかることが多いことが挙げられる。これにより、CIの時間が長くなることで本番のデプロイにかかる時間とコストが増えたり、開発時も一々起動が遅くてアプリケーション開発者に不満が溜まってしまう。
また、AIライブラリはWeb App サーバーのインフラ上で動くため、AI処理をGPUインスタンスで実行するといったことができないほか、AIライブラリのパフォーマンス上の問題がプロダクト全体に及んでしまうという問題点もある。ただし、この問題は、AIモデルの自社でのホスティングを行わず、AIライブラリではプロンプティングとChat GPT 等の外部API コールの制御だけを行うのであれば特に問題とはならない。
分割の目的
これまでのアーキテクチャにおける問題点を整理すると、アーキテクチャを分割する目的が2つ存在していたことが見えてくる。
- 異なるサイクルで開発を行うチーム間の責任境界を引くこと
- AI処理の実行環境をその他のプロダクトから切り離すこと
1つめのチーム間の責任境界について、これは各チームの関心事を分離するためのものであるといえる。
このため、境界の向こう側の実装の詳細を意識する必要がない程度にインターフェースを整える必要はあるが、そのインターフェースはあくまでもチーム間のコミュニケーションのためのものであり、変更や拡張に対して開いている必要がある。
また、2つのチームが互いに依存せず、独自のタイミングでリリースすることができることが重要となる。
2つ目の実行環境の境界について、こちらは依存ライブラリや、メモリ空間、GPUなどの物理構成を分離するための境界で、純粋に技術的な制約によるものである。
このように2つの目的があるところを、上述のアーキテクチャでは1つの境界で達成しようとしていたために問題が生じていたと考えられる。
現在のアーキテクチャ
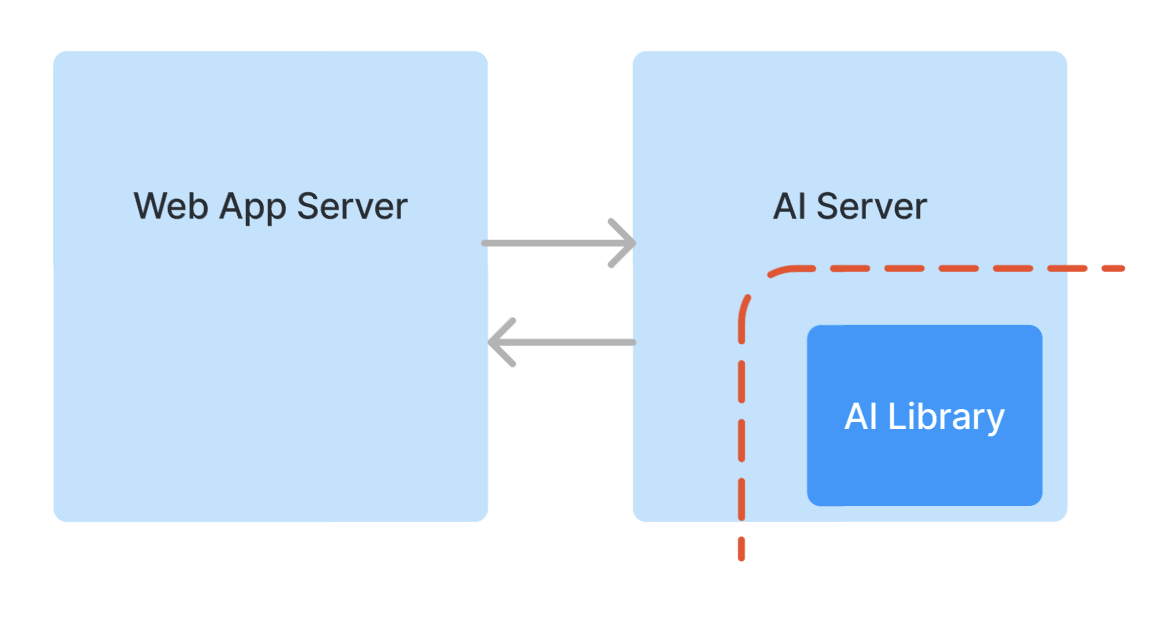
現在、LAPRASでは新たなAI機能を実装する際には以下のようなアーキテクチャを採用している。
- AIでの処理を行うためのAIサーバーを構築する (これはプロダクトチームが担当する)
- 実際のAIの処理は、AIチームが提供するライブラリ(Python パッケージ)の中で行う
つまり、上述の2つの「分割の目的」を達成するために、従来採用していたマイクロサービス化とライブラリ化を組み合わせたアーキテクチャになっている。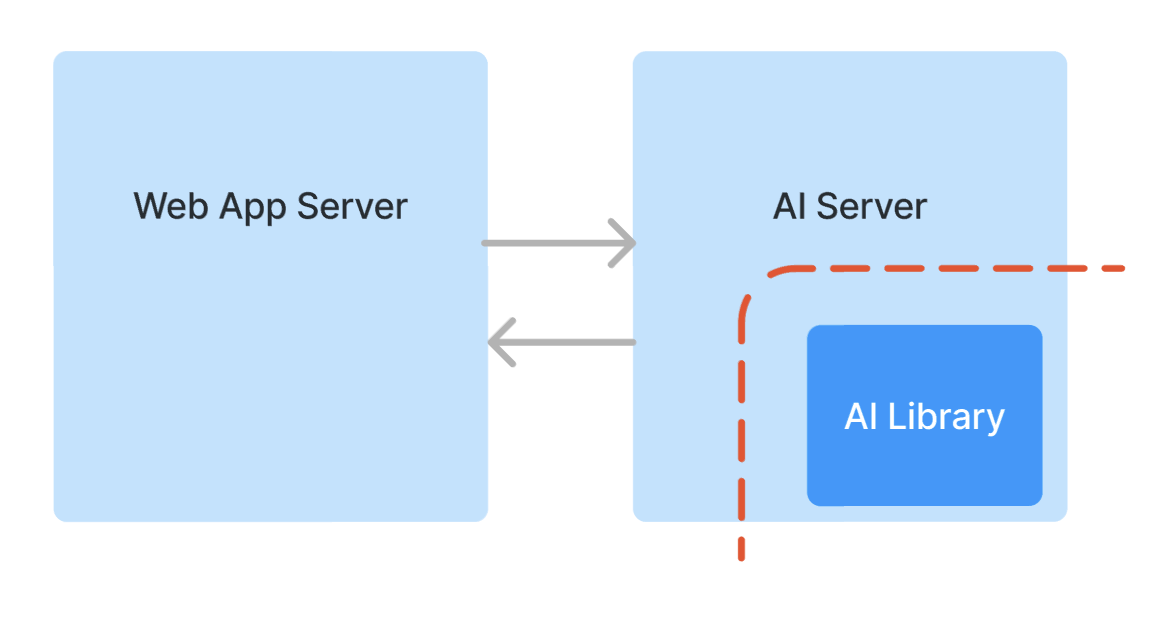
このアーキテクチャでは、AIチームとプロダクトチームの責任境界はAIライブラリのインターフェースと一致する。LLMの場合、AIチームが担当しているプロンプトやLangChainを用いた処理もAIライブラリの中に実装される。
AIライブラリ単体では、ユニットテストや性能評価、ドライバーメトリクスやガードレールメトリクスの計測・記録をコマンド1つで行えるようにし、コミットのタイミングで自動実行できるようにCIを作成する。また、モデルのファインチューニングなどを行う場合には、これもCIに組み込んでおく。
こうすることで、AIチームがモデルやプロンプトを変更した際に各メトリクスがどのように変化したのかを自動で管理できるようになり、方針転換した際のリバートなどもしやすくなる。特に、LLMのプロンプティングは多くの試行錯誤が必要となるが、プロンプトのバージョンごとの結果の自動記録やリバートのしやすいことは、試行錯誤をする際のフットワークを軽くする意味でも重要である。
また、実験に使ったJupyter notebook などもこのリポジトリに入れておき、過去の実験結果や経緯を後から確認できるようにしていく。
AIチームが作成したライブラリは、プロダクトチームがAIサーバーに取り込む。その際には、どのバージョンのライブラリを取り込むのかを指定できるようにしておく。AIライブラリに修正があった場合、プロダクトチームはAIサーバーに新しいライブラリのバージョンを取り込むと同時に、修正版ライブラリを取り込むのに必要な変更を同時にコミットする。
AIサーバーとWebApp サーバーはどちらもプロダクトチームが担当しているため、開発段階でAPIの仕様を変更する場合には、プロダクトチームのタイミングで修正を行うことができる。
このように、マイクロサービスとライブラリ化を組み合わせることで、チーム連携のオーバーヘッドを最小化しつつ、AIチームとプロダクトチームが独立して開発を進めながら必要なタイミングでAIチームの成果をプロダクトチームが取り込むことができる。
将来的に、AIチームが探索よりも運用を重視すべきフェーズとなった時は、AIサーバー全体をAIチームが担当するようにすることで、本来のマイクロサービスに近づけていくこともできる。
まとめ
LLMの登場によってAIを用いたプロダクト開発のスパンが短くなり、ますます「どう作るか」よりも「誰に何を届けるか」が重要となってきている昨今、AIチームの探索的な開発とプロダクトへの組み込みをシームレスに行うことの重要性が高まっている。
本記事では、LAPRASが過去から現在にかけて採用してきたAI関連のアーキテクチャについて詳しく紹介するとともに、LLM時代にあるべきアーキテクチャとチームトポロジーについて考察した。過去のアーキテクチャであるマイクロサービスとライブラリ化で直面した課題を挙げつつ、それらの問題を解決するために採用されている現在のアーキテクチャについても詳述した。
AIチームとプロダクトチームが効率的に協働する上で必要となる責任境界と、技術的要請としての実行環境の境界をそれぞれ設計することで、AIの探索的な開発とプロダクトへの統合を両立させる方法を提案した。
本記事は、あくまでも現時点のLAPRASの組織規模、事業フェーズ、プロダクト特性に基づいた、現時点で適切と考えるアーキテクチャについて述べたものである。今後のAI技術の進化やプロダクトの成長に伴い、新たな課題や要件が浮上してくると考えられる。
そのため、アーキテクチャやチーム構成は、現時点で想定しうる将来の状況は考慮しながらも、その時々で最適な形にアップデートしていくことが重要である。
